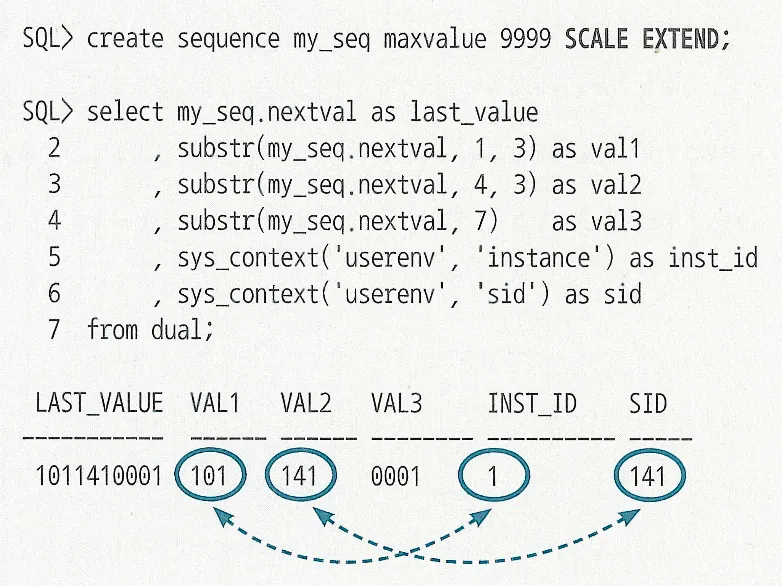
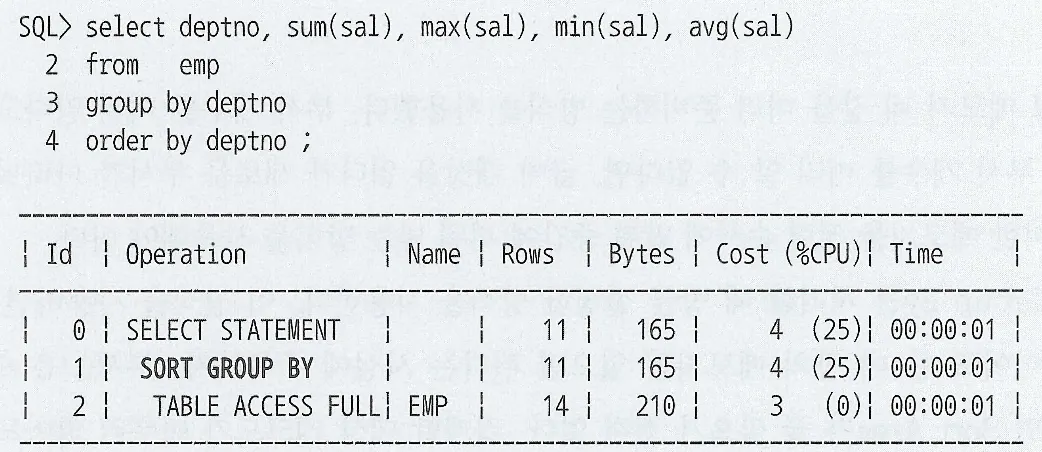
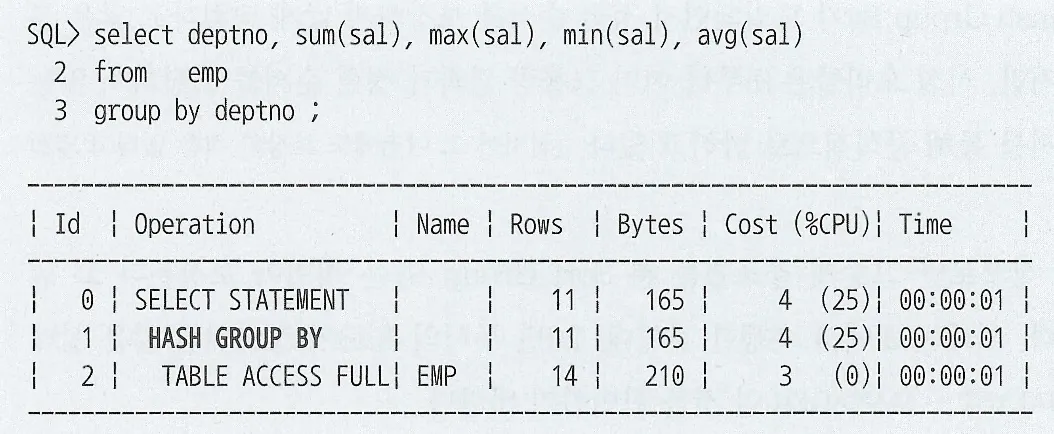
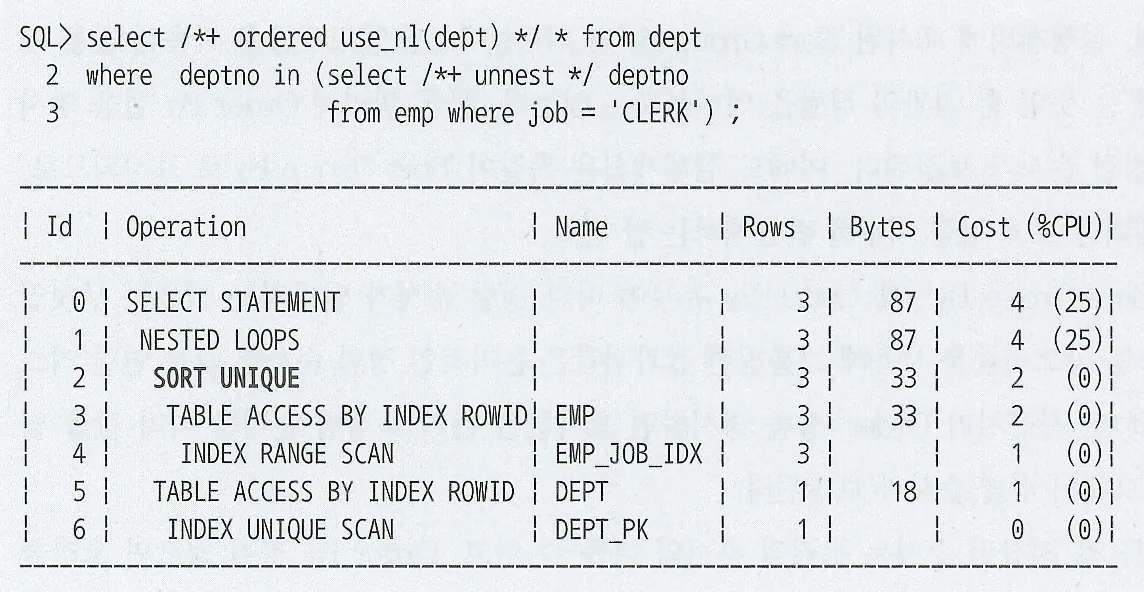
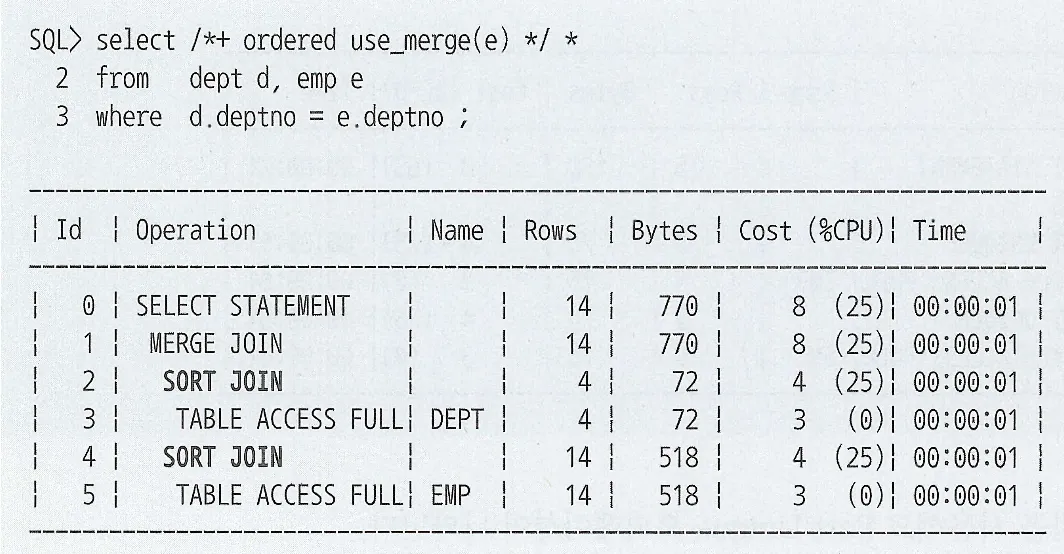
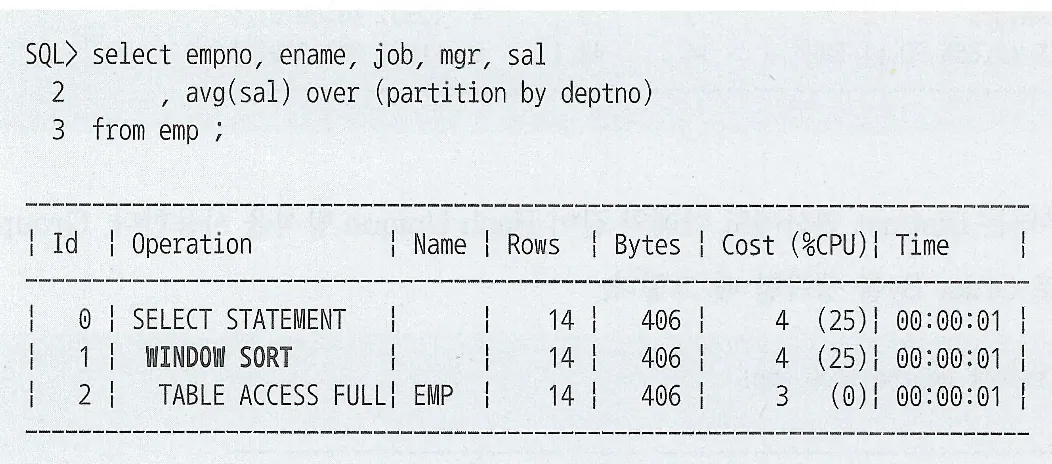
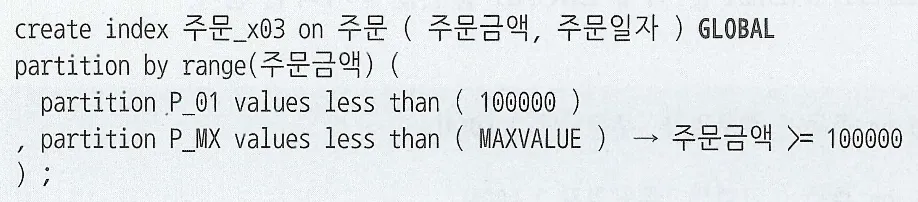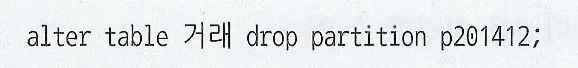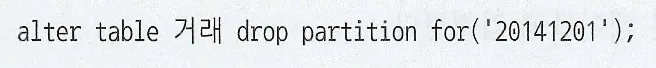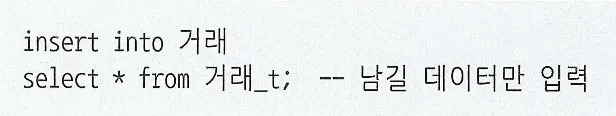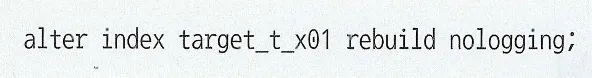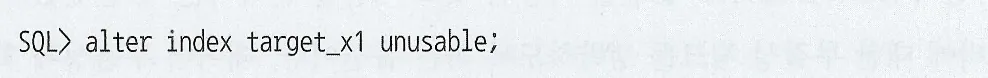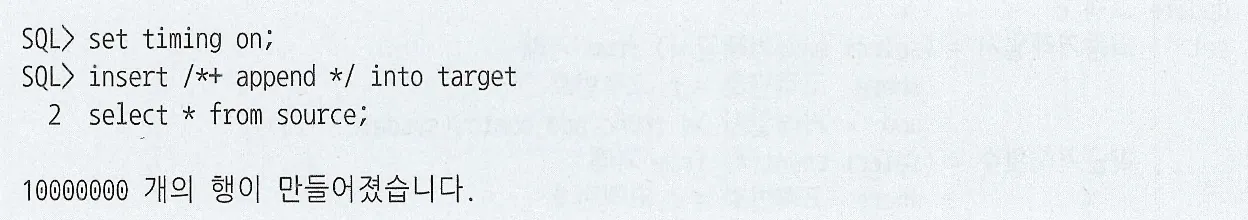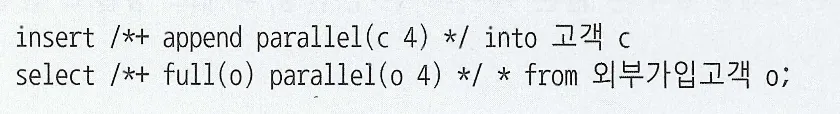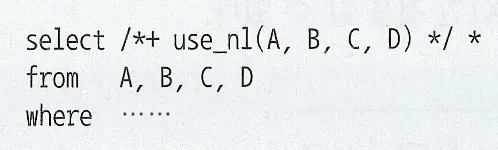HttpsURLConnection은 네트워크 통신 레벨의 API로 SSL 핸드셰이크를 수행
SSLContext는 SSL 세션의 구성요소에 대한 초기화 및 관리르 수행하고 해당 객체에서 암호화 방식이나 TrustManager를 결정
TrustManagerFactory SSLContext에서 사용할 TrustManager 리스트를 생성하는 역할 수행한다 이 때, JVM "cacerts" 또는 사용자 keyStore를 통해 TrustManager 생성
X509TrustManager는 실제 서버 인증서 체인을 검증하는 역할을 수행하며 "checkServerTrusted" 메소드를 통해 서버가 제공한 인증서 체인을 검증
(RestTemplate도 내부적으로 HttpURLConnection을 사용하고 있어 인증 흐름은 동일)
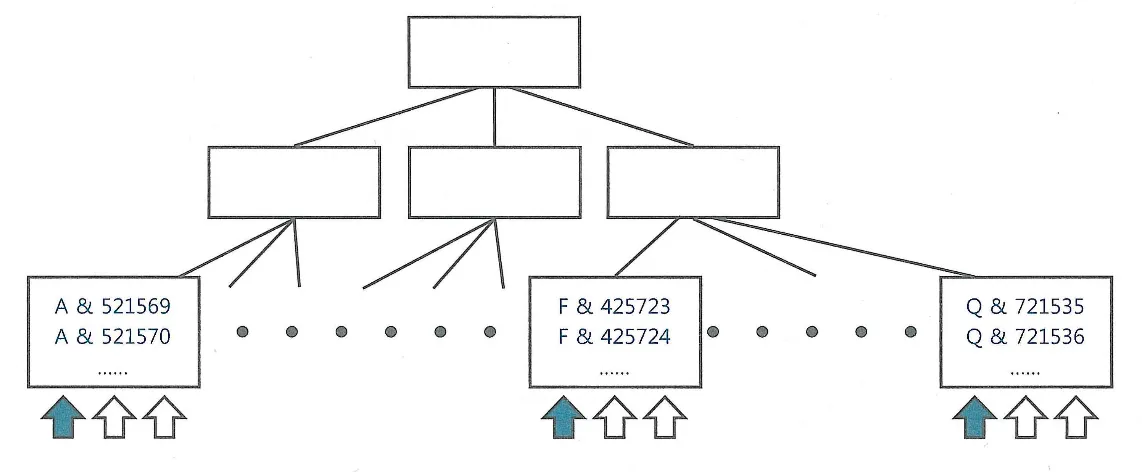
Java 내 cacerts 확인 방법
cd $JAVA_HOME (JAVA가 설치된 디렉토리로 이동)
cd jre/lib/security (cacerts가 있는 위치로 이동)
# 아래 명령을 수행하면 해당 되는 alias에 대한 CA 인증서 정보를 볼 수 있다
keytool -list -v -keystore ./cacerts -storepass [password, 기본 "changeit"] -alias '[alias 명]'
해당 CA인증서를 확인함으로써 인증서의 세대 교체 등이 발생했을 때 신규 인증서를 어플리케이션에서 검증할 수 있는지 확인할 수 있다
추가
어플리케이션 실행할 때 jvm 옵션으로 아래 옵션을 추가하면 HTTPS 요청이 발생할 때 인증서, TLS 버전, 루트 인증서에 대한 정보를 로그로 확인할 수 있다
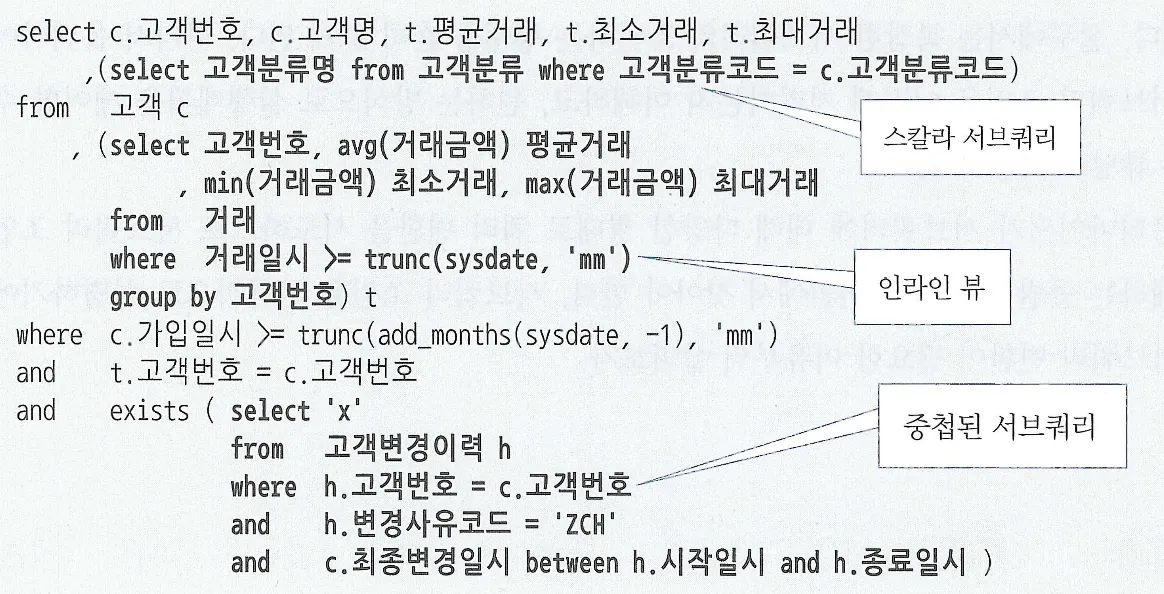
통합테스트를 할 때는 Spring 컨테이너를 통해 필요한 객체를 생성하고 의존성을 주입해야한다
그리고 이를 위해 @SpringBootTest 어노테이션을 붙인다
이를 통해 테스트가 수행될 때 SpringBootTestContextBootstrapper가 동작하면서 ContextLoader를 통해 context(ApplicationContext)를 로드하는 과정에서 캐싱된 context가 있으면 해당 컨텍스트를 재사용하게 된다
- ApplicationContext를 생성하는 비용이 크기 때문에 재사용
@SpringBootTest 동작 흐름
@SpringBootTest
↓
SpringBootTestContextBootstrapper
↓
SpringBootContextLoader.loadContext()
↓
ApplicationContext 생성
↓
의존성 주입
↓
테스트 수행
------------------
@BeforeEach 실행
↓
@Test 실행
↓
@AfterEach 실행
------------------
↓
컨텍스트 캐시 유지 또는 제거
컨텍스트를 재사용하면서 컨텍스트 로드 시점에 동작해야하는 아래 설정 함수가 동작하지 못하고 이로 인해 두번째 테스트에서 redis에 연결을 시도하였으나 실패하면서 테스트가 정상 수행되지 못한 것이다
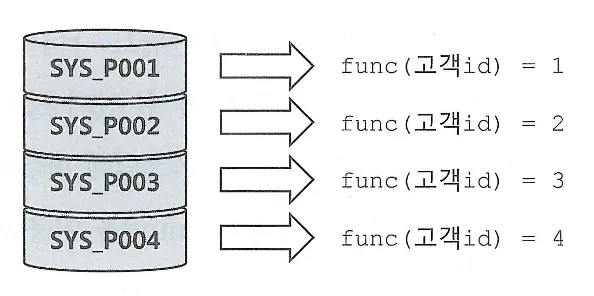
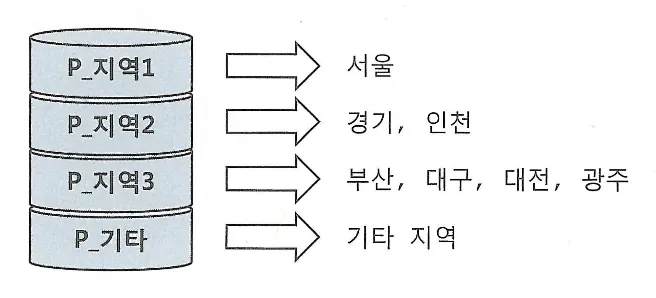
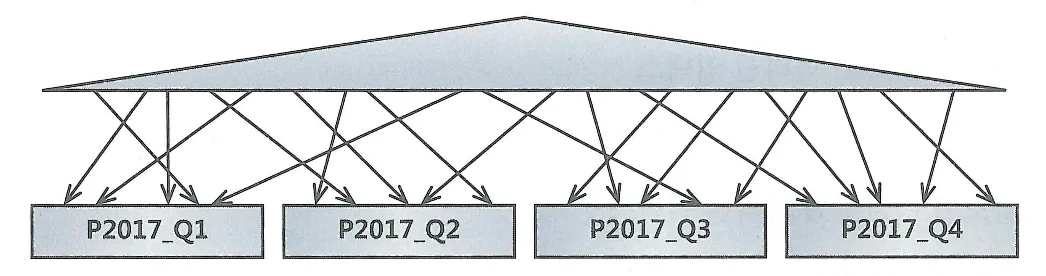
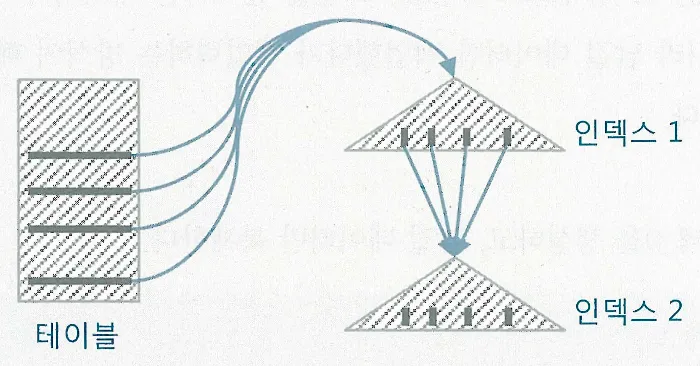
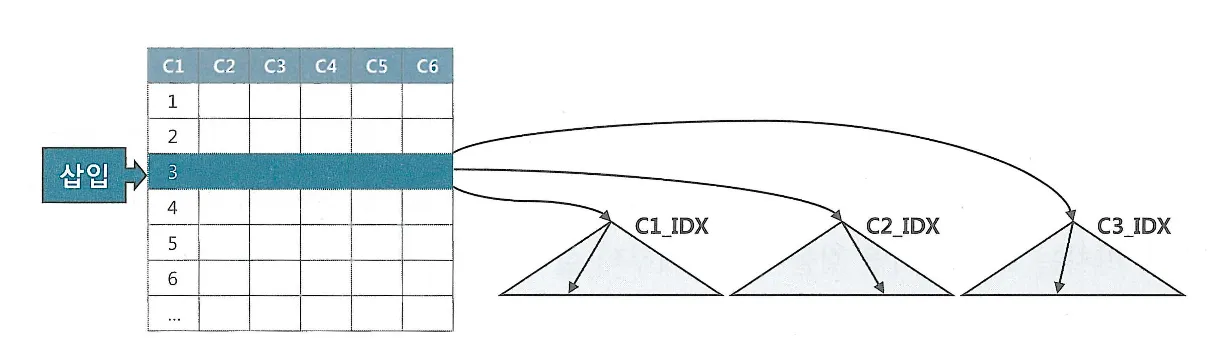
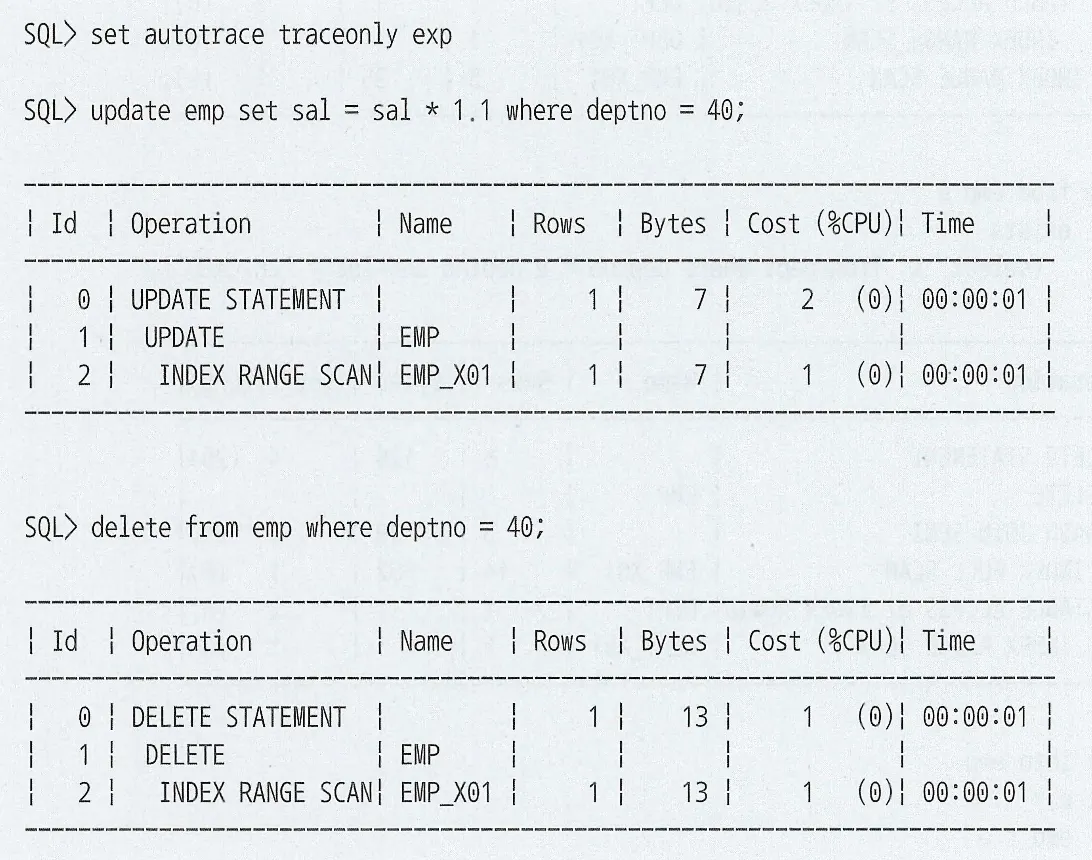
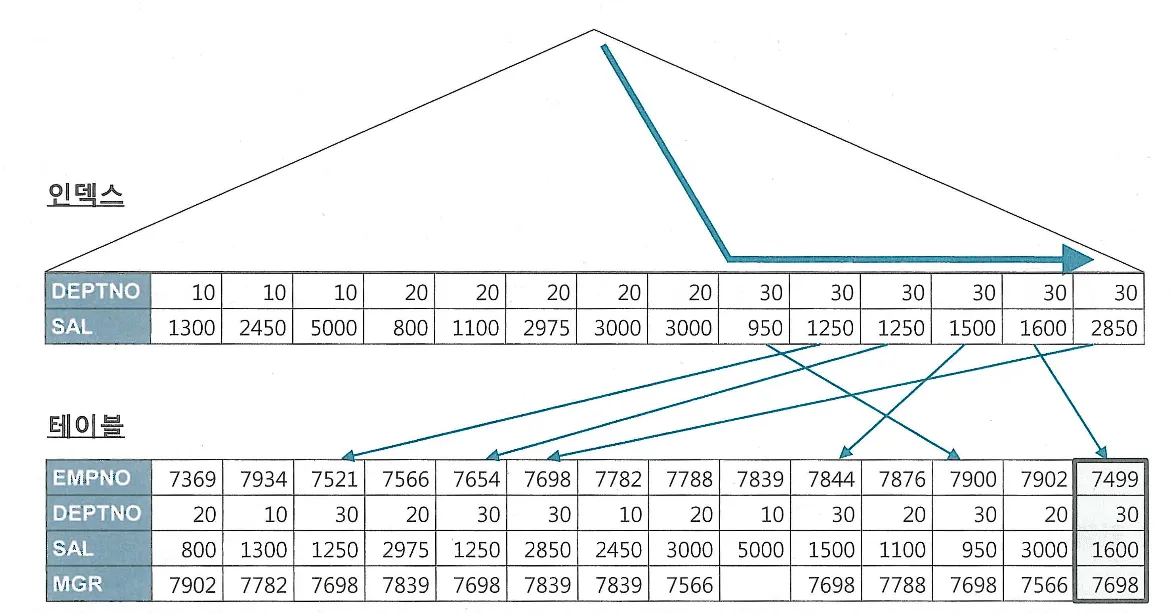
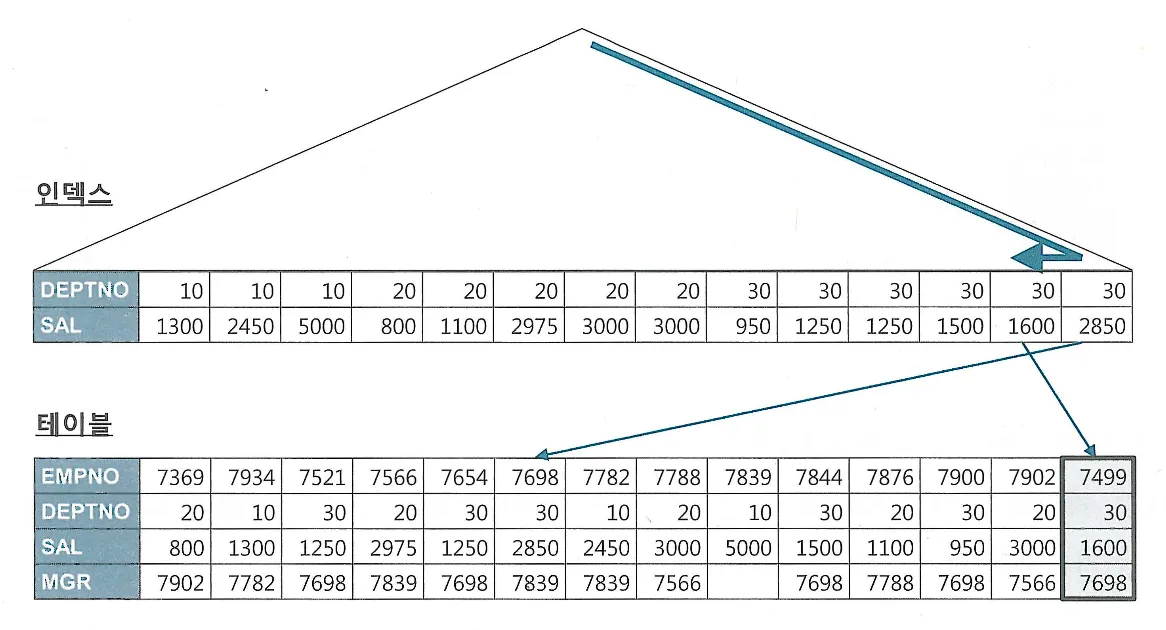
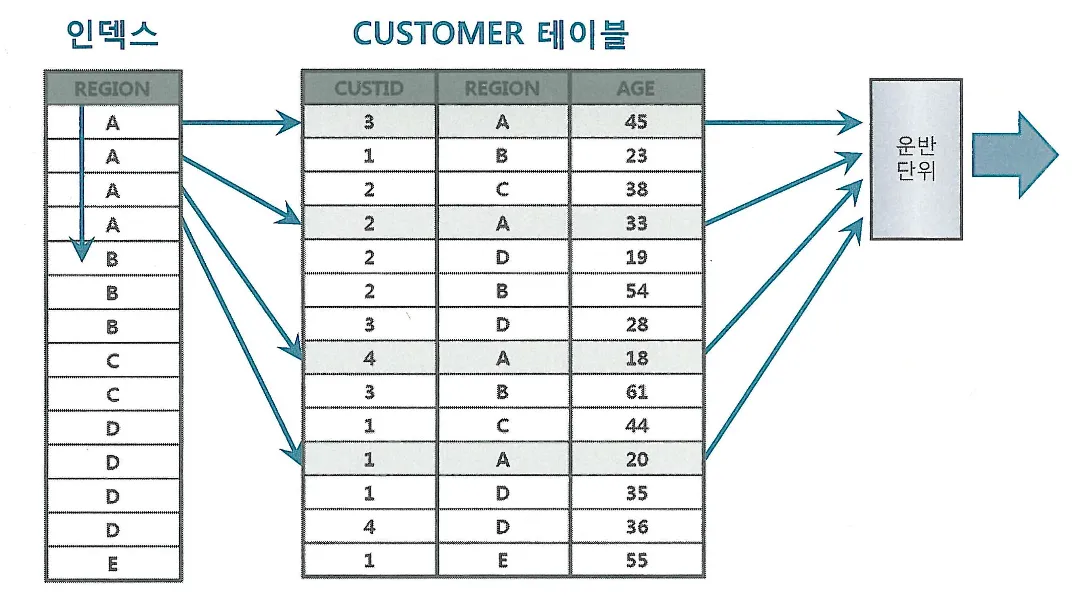
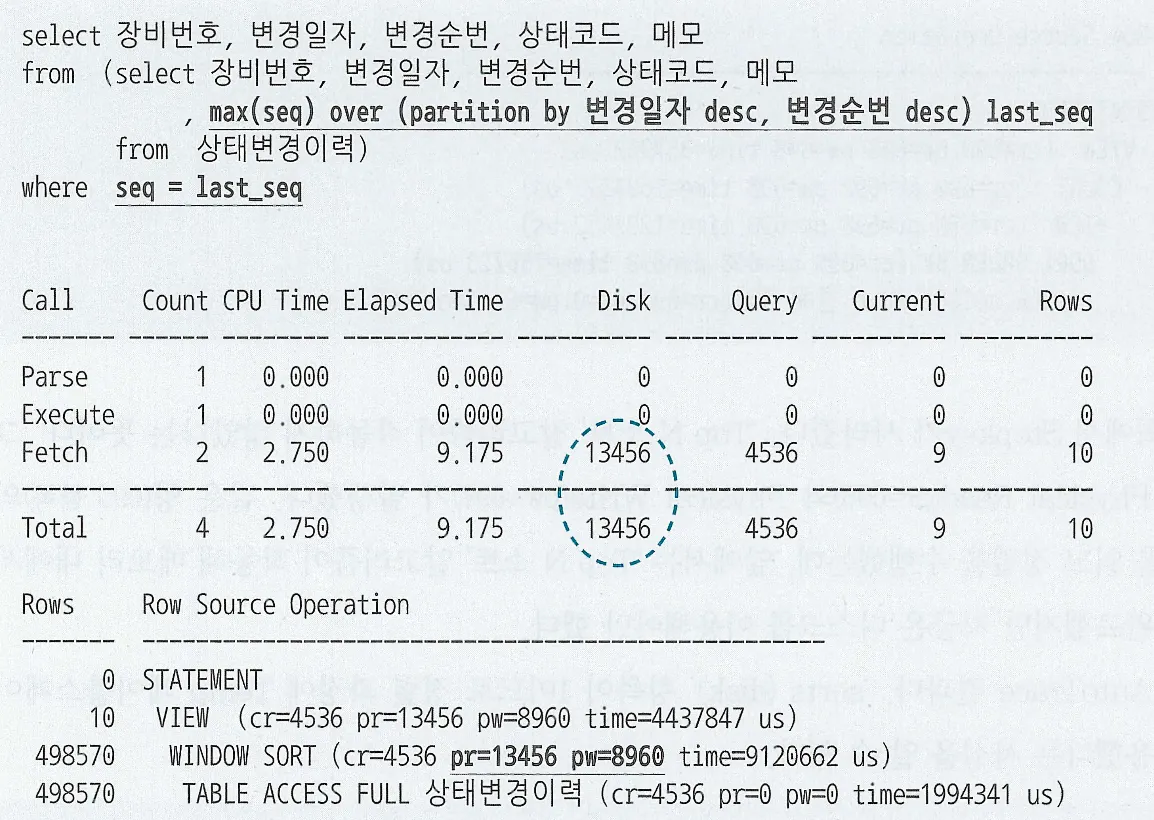
UPDATE의 경우 해당되는 인덱스만 찾아서 변경해주면 된다. 다만, 테이블에서 한건을 변경할 때 마다 인덱스에는 두개의 오퍼레이션이 발생(삭제 후 삽입)
DML에서 인덱스 개수가 미치는 영향이 크다.
핵심 트랜잭션 테이블에서 인덱스의 개수를 하나라도 줄이면 TPS(Transcation Per Second)는 그만큼 향상된다.
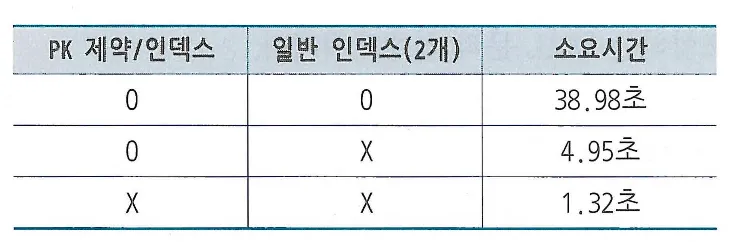
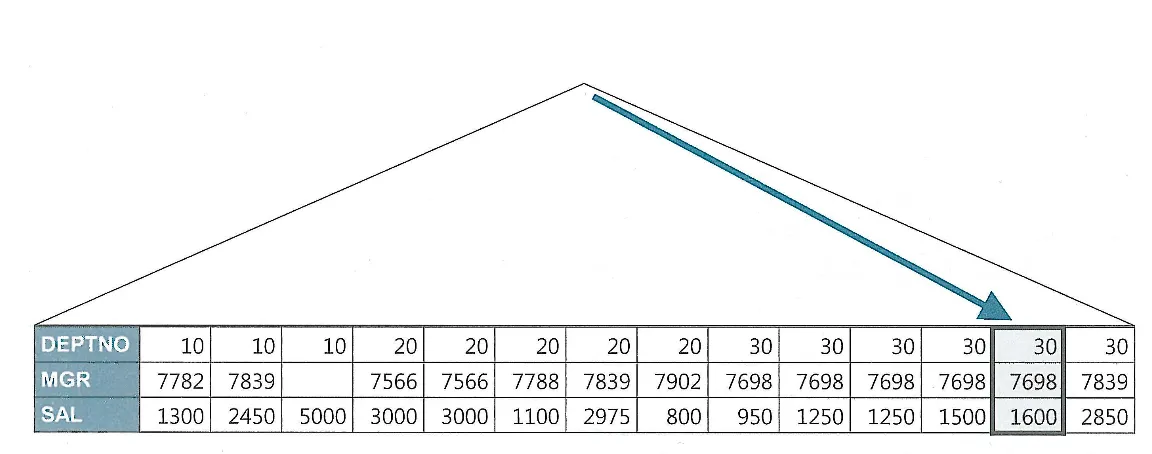
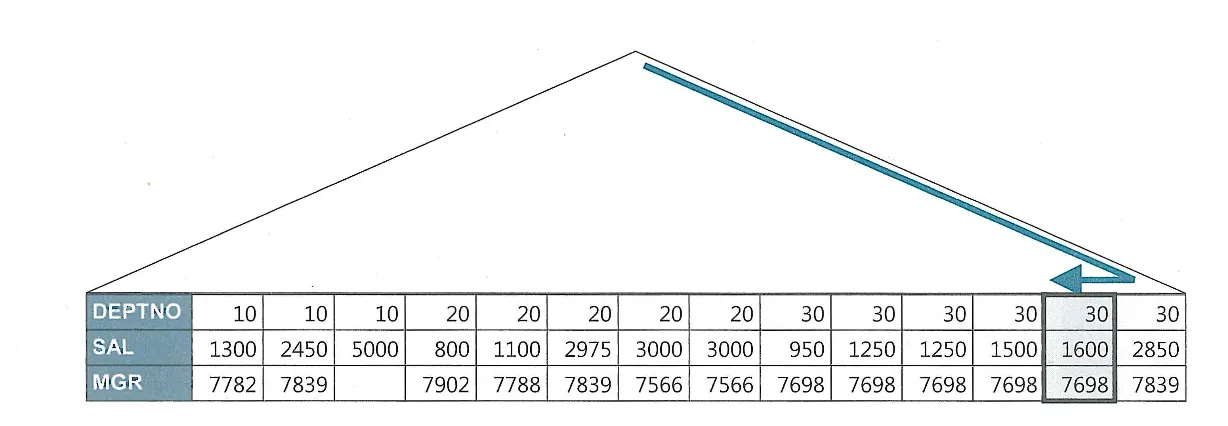
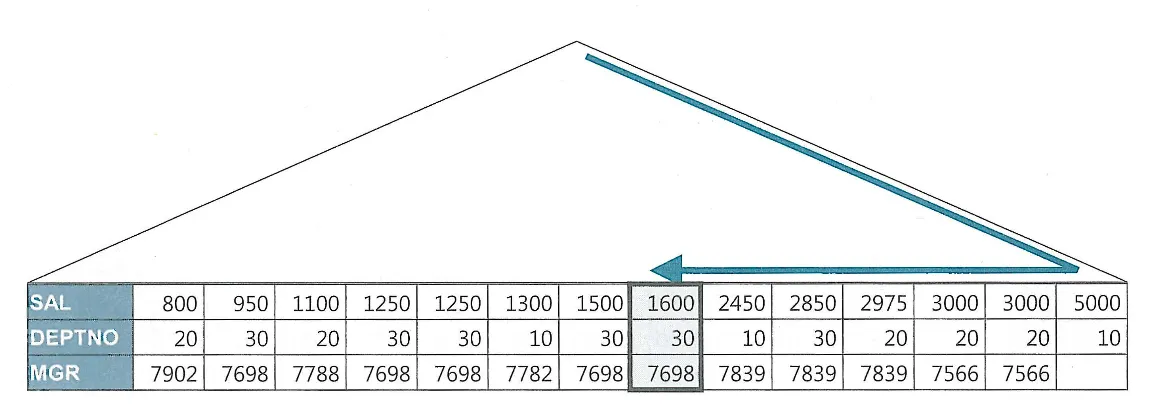
인덱스가 존재할 때와 그러지 않을 때의 insert 시간 비교
왼쪽 인덱스가 없을때, 가운데 인덱스가 2개 존재할 때, 오른쪽 일반 인덱스와 PK 제약을 모두 제거한 상태
데이터베이스에 논리적으로 의미있는 자료만 저장되게 하는 데이터 무결성 규칙
개체 무결성
참조 무결성
도메인 무결성
사용자 정의 무결성
PK, FK 제약은 Check, Not Null 제약보다 성능에 더 큰 영향을 미친다
Check, Not Null은 정의한 제약 조건을 준수하지는만 확인하면 되지만, PK, FK 제약은 실제 데이터를 조회해 봐야 하기 때문
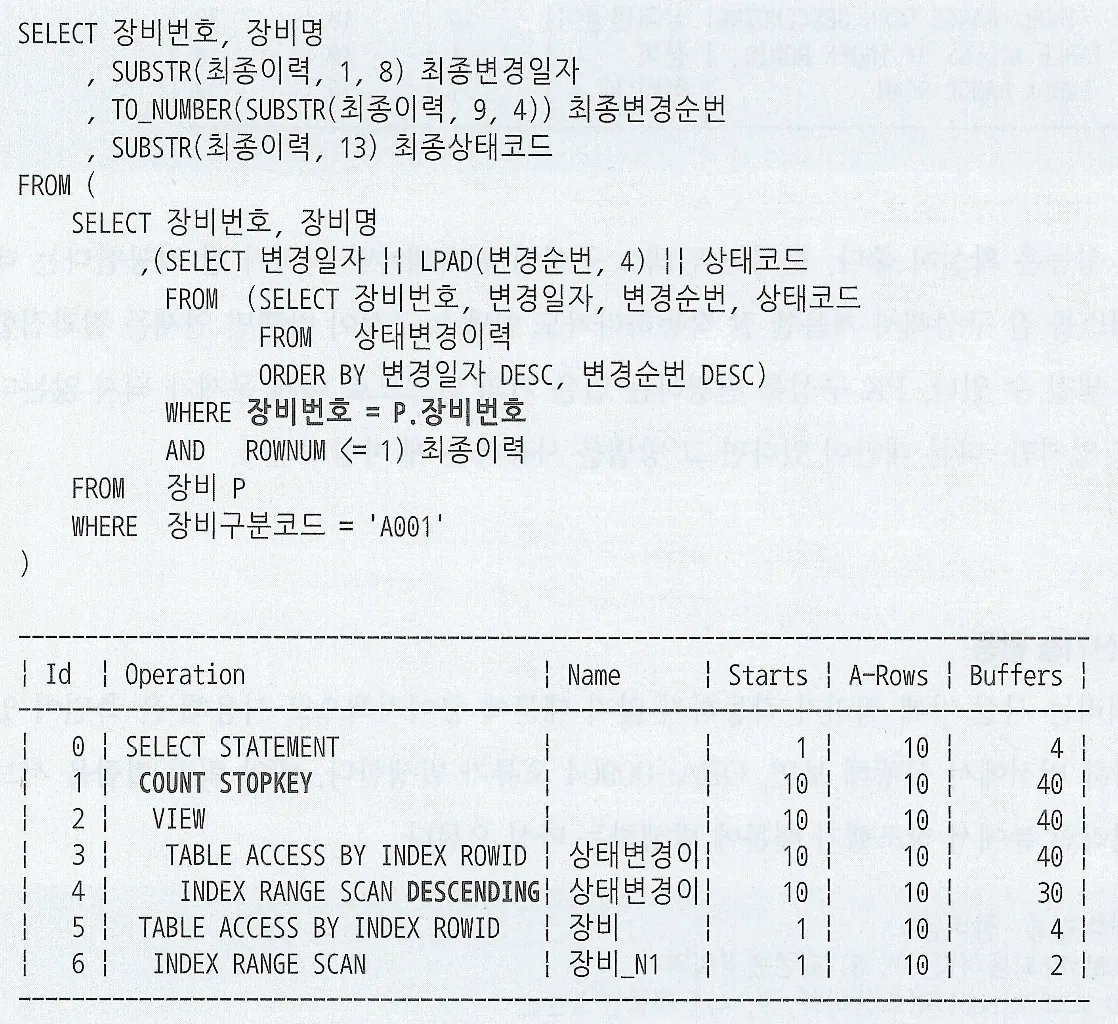
Update, Delete 문의 실행 계획이 Select 문의 실행 계획과 다르지 않으므로 인덱스 튜닝 원리를 그대로 적용할 수 있다. 조인 튜닝 또한 동일하게 적용 가능하다
인덱스도 select와 같이 적용된다
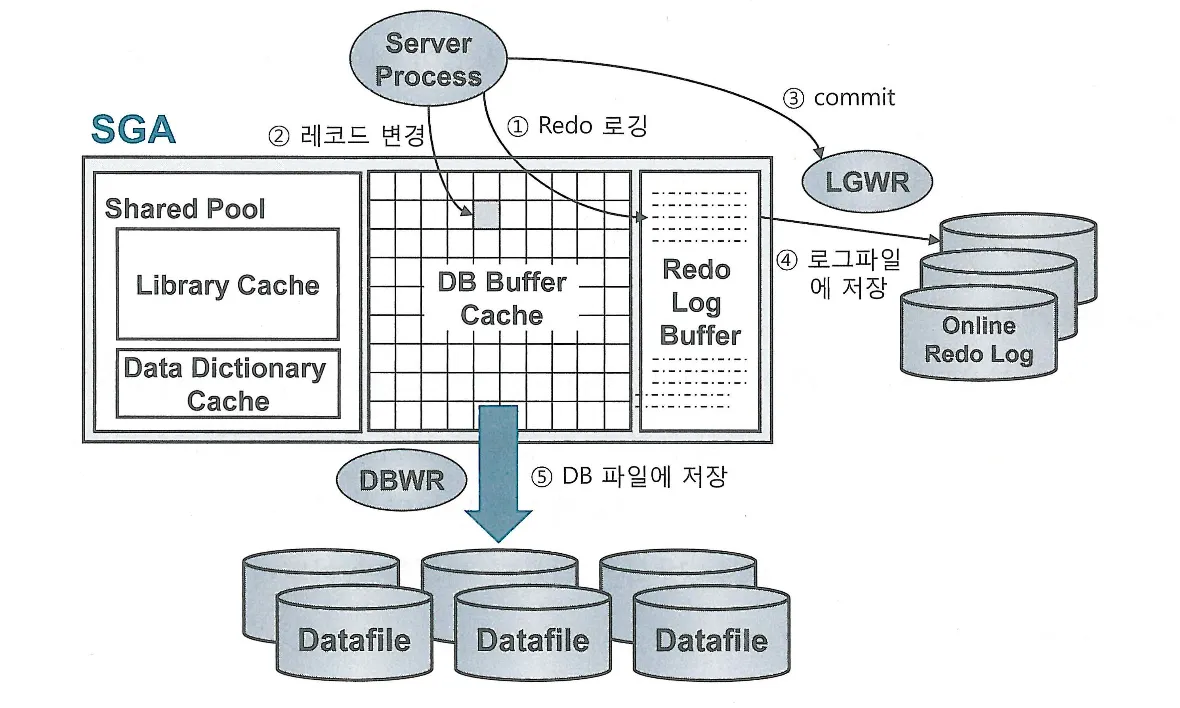
Redo 로깅과 DML 성능
데이터파일과 컨트롤 파일에 가해지는 모든 변경사항을 Redo 로그에 기록한다
Redo 로그는 트랜잭션 데이터가 어떤 이유에서건 유실되었을 때, 트랜잭션을 재현함으로써 유실 이전 상태로 복구하는데 사용된다
DML이 수행될 때마다 Redo 로그를 생성하므로 Redo 로깅은 DML 성능에 영향을 미친다
Redo 로그 목적
Database Recovery : Media Fail 발생 시 데이터베이스를 복구하기 위해 사용(온라인 Redo 로그를 백업해 둔 Archived Redo 로그 이용) → Media Recovery
Cache Recovery (Instnace Recovery 시 roll forward 단계) : 캐시에 저장된 변경사항이 디스크 상의 데이터 블록에 기록되지 않은 상태로 인스턴스가 비정상적으로 종료되면, 그때까지의 작업내용을 모두 잃게 된다.(버퍼캐시는 휘발성) 트랜잭션 데이터 유실에 대비하기 위해 Redo 로그를 남긴다
Fast Commit : 변경된 메모리 버퍼 블록을 디스크 상의 데이터 블록에 반영하는 작업은 랜덤 액세스 방식으로 이루어지므로 매우 느리지만 로그는 Append 방식으로 기록하므로 상대적으로 빠르다. 따라서 변경사항을 Append 방식으로 빠르게 로그 파일에 기록하고 변경된 메모리 버퍼 블록과 데이터 파일 블록 간 동기화는 DBWR을 이용해 나중에 배치 방식으로 일괄 수행한다. 아직 디스크에 기록되지 않았지만 Redo 로그를 믿고 커밋을 완료하는 것을 Fast Commit 이라고 한다
Undo 로깅과 DML 성능
Redo는 트랜잭션을 재현함으로써 과거를 현재 상태로 되돌리는 데 사용 Undo는 트랜잭션을 롤백함으로써 현재를 과거로 돌리는데 사용
Undo 데이터 사용 조건
Transaction Rollback : 트랜잭션에 의한 변경사항을 최종 커밋하지 않고 롤백할 때 Undo 데이터 사용
Transaction Recovery (Instance Recovery 시 rollback 단계) : Instance Crash 발생 후 Redo를 이용해 roll forward 단계가 완료되면 최종 커밋되지 않은 변경사항까지 모두 복구되므로 Undo 데이터를 사용하여 아직 커밋되지 않았던 트랜잭션들을 모두 롤백해야 한다
Read Consistency : 읽기 일관성에 사용
MVCC(Multi Version Concurrency Control) 모델
current 모드: 디스크에서 캐시로 적재된 원본 블록을 현재 상태 그대로 읽는 방식
consistent 모드: 쿼리가 시작된 이후에 다른 트랜잭션에 의해 변경된 블록을 만나면 원본 블록으로부터 복사본(CR Copy) 블록을 만들고 거기에 Undo 데이터를 적용함으로써 쿼리가 시작된 시점으로 되돌려 읽는 방식
SCN(System Commit Number) 마지막 커밋이 발생한 시점정보
블록 SCN: 각 블록이 마지막으로 변경된 시점을 관리하기 위해 블록 헤더에 기록됨
쿼리 SCN: 모든 쿼리는 Global 변수인 SCN 값을 먼저 확인하고 읽기 작업 시작, 이를 쿼리 SCN이라고 한다
데이더를 읽다가 블록 SCN이 쿼리 SCN보다 더 큰 블록을 만나면 복사본 블록을 만들고 Undo 데이터를 적용함으로써 쿼리가 시작된 시점으로 되돌려서 읽는다
Undo 데이터가 다른 트랜잭션에 의해 재사용됨으로써 쿼리 시작 시점으로 되돌리는 작업에 실패할 때 Snapshot too old 에러 발생
Lock과 DML 성능
Lock은 DML 성능에 매우 크고 직접적인 영향을 미친다. Lock을 필요 이상으로 자주, 길게 사용하거나 레벨이 높을수록 DML 성능은 느려진다
트랜잭션 격리 수준
Read Uncommited
Read Commited (기본)
Reapeatable Read
Serializable
트랜잭션의 저장 과정 (Write Ahead Logging)
DML 문을 실행하면 Redo 로그버퍼에 변경사항 기록
버퍼블록에서 데이터를 변경(추가,수정,삭제), 버퍼캐시에서 블록을 찾지 못하면 데이터파일에서 읽는 작업부터 수행
커밋
LGWR 프로세스가 Redo 로그버퍼 내용을 로그파일에 일괄 저장
DBWR 프로세스가 변경된 버퍼블록들을 데이터파일에 일괄 저장
Log Force at Commit : 서버 프로세스가 커밋을 발행했다고 신보를 보낼때 LGWR 프로세스가 로그파일에 저장하므로 적어도 커밋시점에는 Redo 로그버퍼 내용이 로그파일에 기록됨
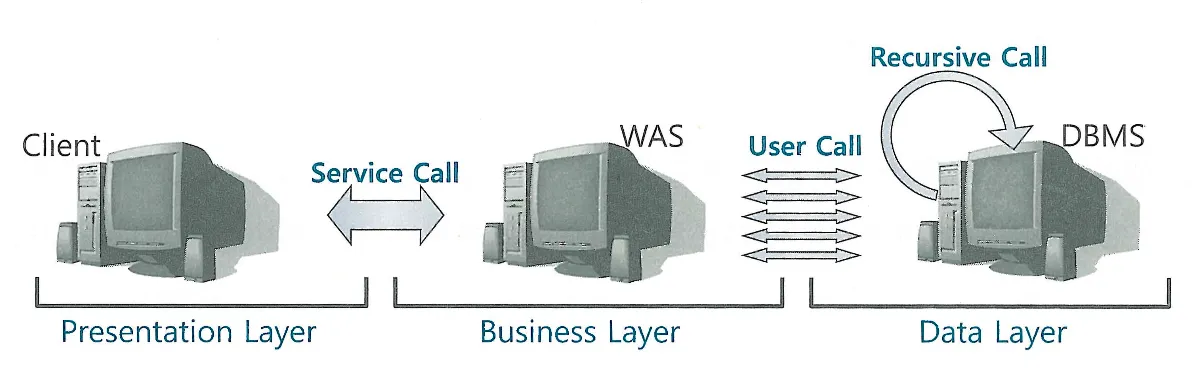
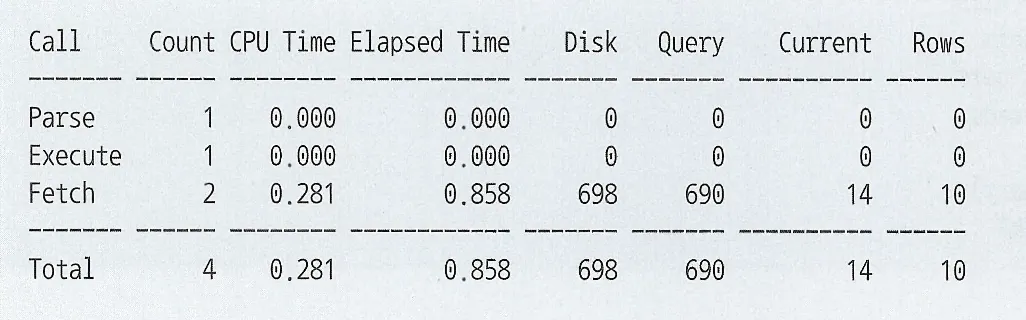
데이터베이스 Call
Parse Call : SQL 파싱과 최적화를 수행하는 단계. SQL과 실행계획을 라이브러리 캐시에서 찾으면, 최적화 단계 생각 가능
Execute Call: SQL을 실행하는 단계. DML은 이 단계에서 모든 과정이 종료. SELET 문은 Fetch 단계를 거친다
Fetch Call: 데이터를 읽어서 사용자에게 결과집합을 전송하는 과정. SELECT문에서만 나타나며 전송할 데이터가 많으면 Fetch Call 여러번 발생
User Call, Recursive Call
Call 이 발생하는 위치에 따라 User Call과 Recursive Call로 나뉜다
User Call: 네트워크를 통해 DBMS 외부로부터 인입되는 Call 3-Tier 아키텍처에서 User Call은 WAS(또는 AP서버) 서버에서 발생하는 Call
Recursive Call: DBMS 내부에서 발생하는 Call
커밋과 성능
: 커밋을 자주하는 경우 트랜잭션 원자성에 문제가 생긴다
: 매우 오래 걸리는 트랜잭션을 한 번도 커미하지 않고 진행하면 Undo 공간 부족으로 인해 시스템에 부작용을 초래할 수 있다
: 적당한 주기로 커밋을 하는것이 좋다
커밋을 자주하면 수행 시간이 오래걸리게 되는데, 이는 User Call에서는 더 많은 시간이 걸리게 된다
One SQL
Insert Into Select
수정가능 조인 뷰
Merge 문
실무에서 One SQL로 구현이 쉽지 않다
Array Processing 기능을 활용하면 One SQL을 쓰지 않고도 Call 부하를 획기적으로 줄일 수 있다
PL/SQL
Java
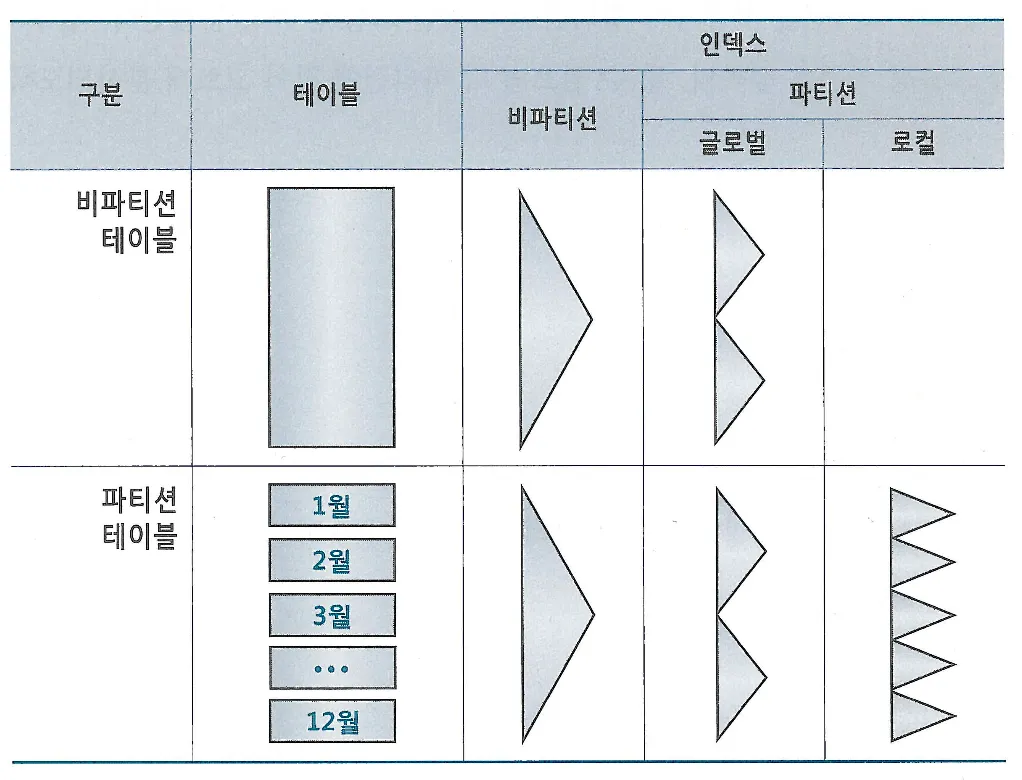
인덱스 및 제약 해제를 통한 대량 DML 튜닝
동시 트랜잭션 없이 대량 데이터를 적재하는 배치 프로그램에서는 인덱스 및 제약 조건을 해제함으로써 큰 성능 개선 효과를 얻을 수 있다
PK 제약 및 인덱스 생성 (총 인덱스 2개)
PK제약과 인덱스 해제
PK제약에 Unique 인덱스를 사용한 경우
PK 제약 해제 및 인덱스 삭제
인덱스 비활성화
PK 제약 설정 및 인덱스 활성화
2.PK제약에 Non-Unique 인덱스 사용
PK제약을 Unusable한 상태에서는 데이터를 입력할 수 없다
PK 인덱스를 Drop 하지 않고 Unusable 상태에서 데이터를 입력하려면 PK 제약에 Non-Unique 인덱스를 사용하면 된다
Non-Unique 인덱스 생성 및 PK 제약으로 지정
PK 제약 해제 및 인덱스 비활성화
PK 제약 설정 및 인덱스 활성화
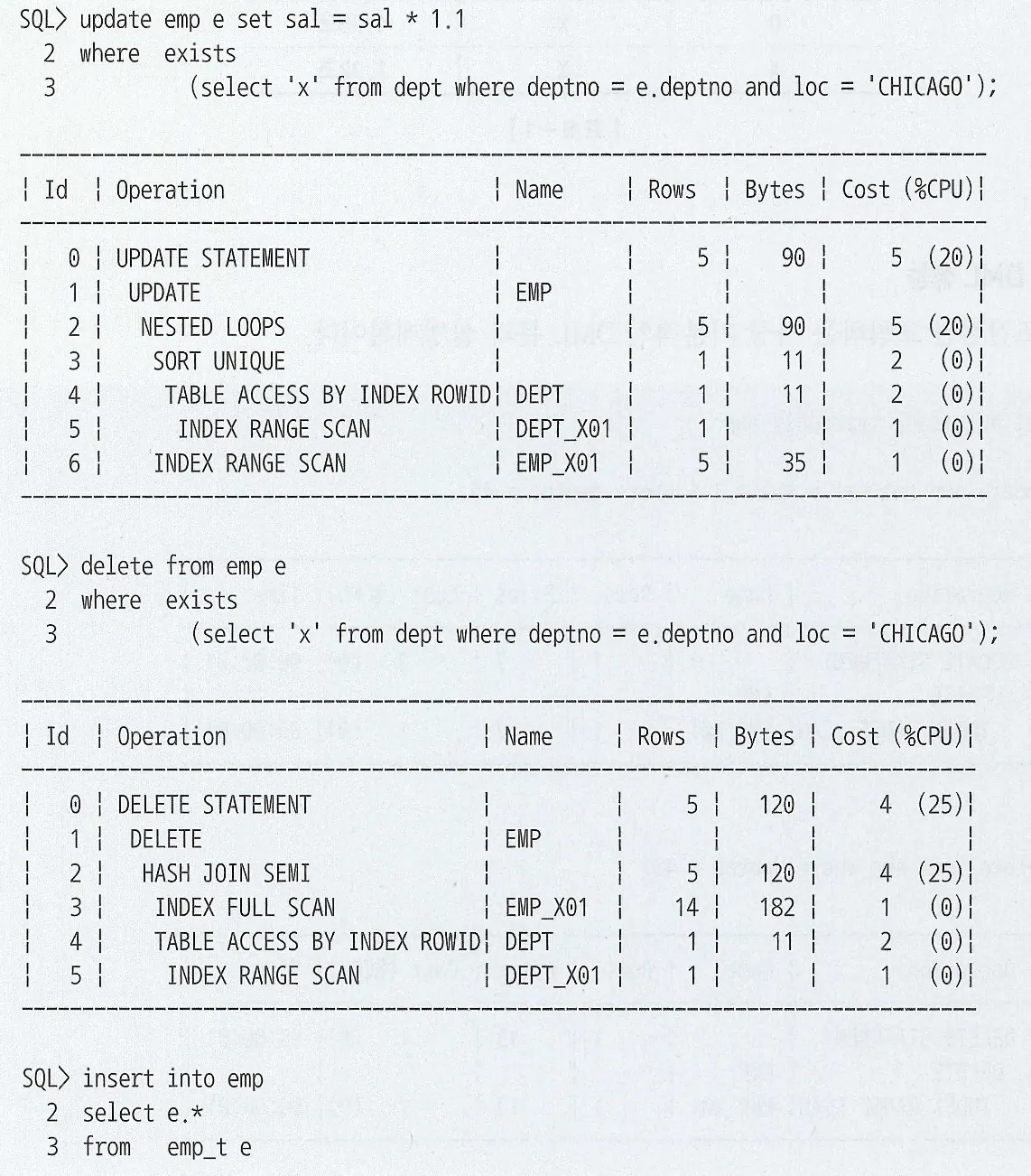
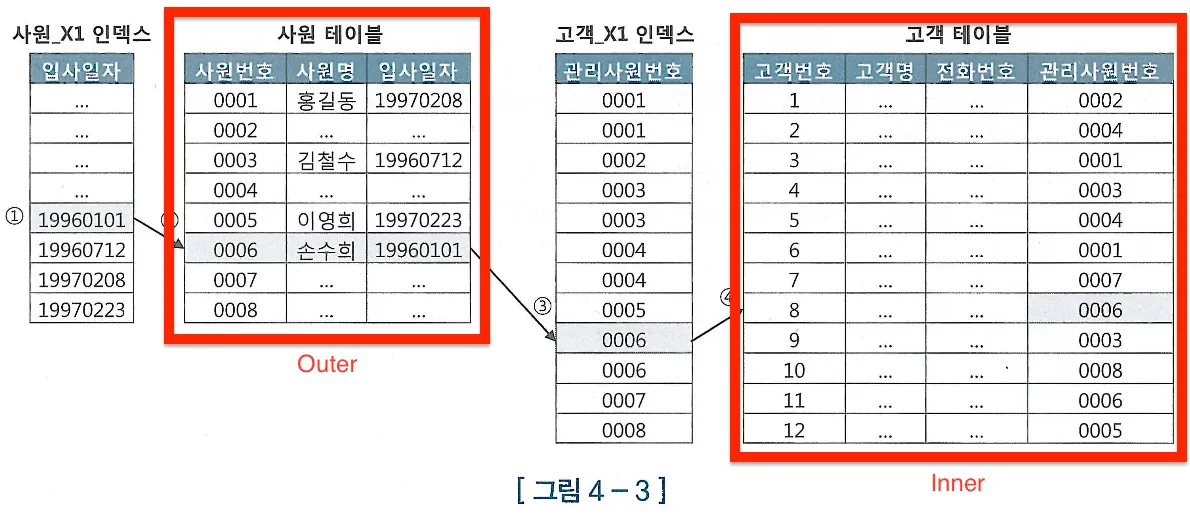
수정가능 조인 뷰
전통적인 UPDATE
전통적인 UPDATE문은 다른 테이블과 조인이 필요할 때 비율을 완전히 해소할 수 없다
수정가능 조인 뷰
수정가능 조인 뷰를 활용하면 참조 테이블과 두 번 조인하는 비효율을 없앨 수 있다
수정가능 조인 뷰에서는 1쪽 집합에 PK 제약을 설정하거나 Unique 인덱스를 생성해야 수정가능 조인뷰를 통한 입력/수정/삭제가 가능하다
키 보존 테이블
: 조인된 결과집합을 통해서도 중복 값 없이 Unique 하게 식별이 가능한 테이블 Unique한 1쪽 집합과 조인되는 테이블이어야 조인된 결과집합을 통한 식별이 가능
ORA-01779 오류 회피 : Group By 한 집합과 조인한 테이블은 키가 보존되므로 해당 문제를 해결할 수 있다
Merge 문
DW Merge 예시
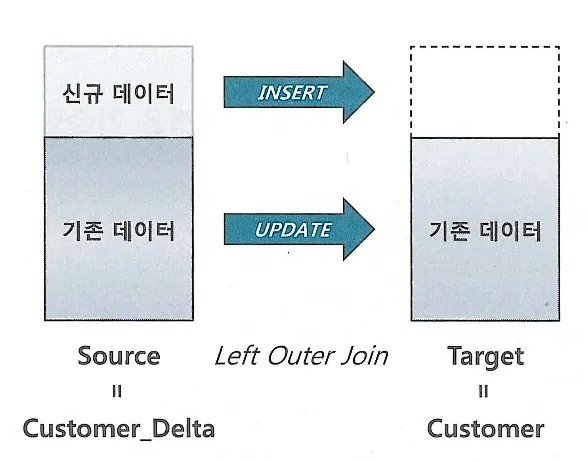
Merge문은 Source 테이블 기준으로 Target 테이블과 Left Outer 방식으로 조인해서 조인 성공하면 Update, 실패하면 Insert 한다
Update 와 Insert를 선택적으로 처리 가능
where 절을 통한 추가 조건절 기술 가능
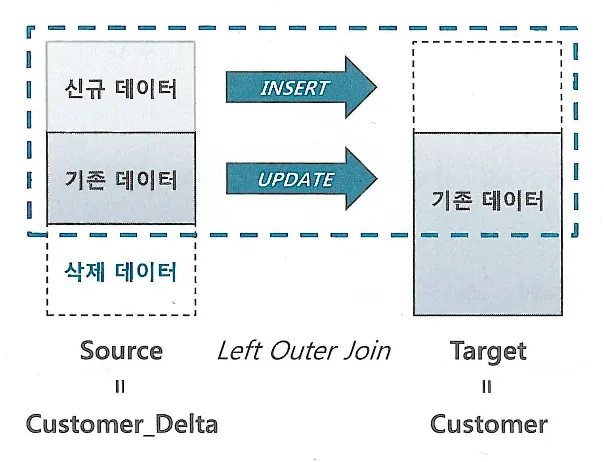
이미 저장된 데이터를 조건에 따라 지우는 기능 제공
Delete의 경우
Merge문을 수행한 결과가 Null 이면 삭제하지 않는다
조인에 성공한 데이터만 삭제할 수 있다
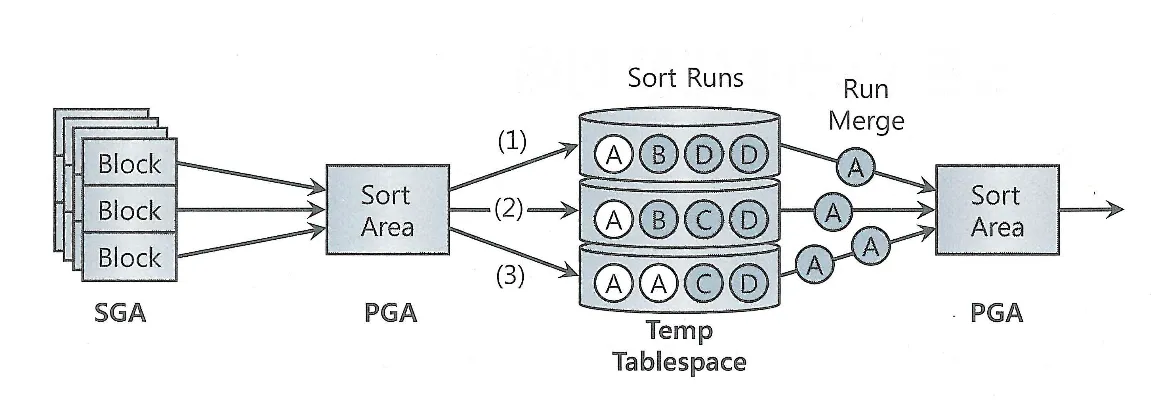
Direct Path I/O
DW, 배치 프로그램에서는 대량 데이터를 처리하기 때문에 버퍼캐시를 경유하는 I/O 메커니즘이 오히려 성능을 떨어뜨릴 수 있다
그래서 버퍼캐시를 경유하지 않고 곧바로 데이터 블록을 읽고 쓸 수 있는 Direct Path I/O 기능을 제공한다
동작하는 경우
병렬 쿼리로 Full Scan을 수행할 때
병렬 DML을 수행할 때
Direct Path Insert 를 수행할 때
Temp 세그먼트 블록들을 읽고 쓸 때
direct 옵션을 지정하고 export를 수행할 때
nocache 옵션을 지정한 LOB 컬럼을 읽을 때
Direct Path Insert
INSERT가 느린 이유
데이터를 입력할 수 있는 블록을 Freelist에서 찾는다
Freelist에서 할당 받은 블록을 버퍼캐시에서 찾는다
버퍼캐시에 없으면, 데이터 파일에서 읽어 버퍼캐시에 적재한다
INSERT 내용을 Undo 세그먼트에 기록한다
INSERT 내용을 Redo 로그에 기록한다
Direct Path Insert 적용 방법
INSERT … SELECT 문에 append 힌트 적용
parallel 힌트를 이용해 병렬 모드로 INSERT
direct 옵션을 지정하고 SQL Loader(sqlldr)로 데이터 적재
CTAS 문 수행
Direct Path Insert 방식이 빠른 이유
Freelist를 참조하지 않고 HWM(High-Water Mark) 바깥 영역에 데이터를 순차적으로 입력한다
블록을 버퍼캐시에서 탐색하지 않는다
버퍼캐시에 적재하지 않고, 데이터파일에 직접 기록한다
Undo 로깅을 하지 않는다
Redo 로깅을 안하게 할 수 있다(nologging 모드 상태일 때)
Direct Path Insert 주의점
exclusive 모드 TM Lock 발생
Freelist를 조회하지 않고 HWM 바깥 영역을 입력하므로 테이블에 여유공간이 있어도 재사용하지 않는다
병렬 DML
INSERT는 append 힌트로 Direct Path Write 방식을 유도할 수 있지만, UPDATE, DELETE 는 불가능하다
병렬 DML로 Direct Path Write 방식 사용가능
병렬 DML 활성화 방법
아래 힌트 적용 시 대상 레코드 찾는 작업(insert는 select 쿼리, update/delete 는 조건절 검색)과 데이터 추가/변경/삭제 병렬로 진행
병렬 DML을 활성화 하지 않고 수행하면 대상 레코드를 찾는 작업만 병렬로 진행되어 추가/변경/삭제 는 QC(Query Coordinator)가 혼자 담당하므로 병목 발생
병렬 INSERT는 append 힌트를 적용하지 않아도 Direct Path Insert 방식을 사용한다
하지만 병렬 DML이 작동하지 않을 경우를 대비해 apeend 힌트를 같이 사용하는 것이 좋다
병렬 DML이 작동하지 않더라도 QC 가 Direct Path Insert를 사용하면 어느정도 만족할 만한 성능을 낼 수 있기 때문
enable_parallel_dml 힌트를 통해 활성화 가능(12c이후)
* 병렬 DML도 Direct Path Write 방식을 사용하므로 데이터 입력/수정/삭제 때 Exclusive 모드 TM Lock 발생
병렬 DML 동작 확인 방법
UPDATE 가 PX COORDINATOR 아래 쪽애 나타나면 UPDATE를 각 병렬 프로세스가 처리